第一部分
閱讀 Zen of Python,在Python解析器中輸入 import this. 一個犀利的Python新手可能會注意到"解析"一詞, 認為Python不過是另一門腳本語言. "它肯定很慢!"
毫無疑問:Python程序沒有編譯型語言高效快速. 甚至Python擁護者們會告訴你Python不適合這些領域. 然而,YouTube已用Python服務於每小時4千萬視頻的請求. 你所要做的就是編寫高效的代碼和需要時使用外部實現(C/C++)代碼. 這裡有一些建議,可以幫助你成為一個更好的Python開發者:

>>> #This is good to glue a large number of strings
>>> for chunk in input():
>>> my_string.join(chunk)
3. 使用Python多重賦值,交換變量
這在Python中即優雅又快速:
>>> x, y = y, x
這樣很慢:
>>> temp = x
>>> x = y
>>> y = temp
4. 儘量使用局部變量
Python 檢索局部變量比檢索全局變量快. 這意味著,避免 "global" 關鍵字.
5. 儘量使用 "in"
使用 "in" 關鍵字. 簡潔而快速.
>>> for key in sequence:
>>> print 「found」
6. 使用延遲加載加速
將 "import" 聲明移入函數中,僅在需要的時候導入. 換句話說,如果某些模塊不需馬上使用,稍後導入他們. 例如,你不必在一開使就導入大量模塊而加速程序啟動. 該技術不能提高整體性能. 但它可以幫助你更均衡的分配模塊的加載時間.
7. 為無限循環使用 "while 1"
 有時候在程序中你需一個無限循環.(例如一個監聽套接字的實例) 儘管 "while true" 能完成同樣的事, 但 "while 1" 是單步運算. 這招能提高你的Python性能.
有時候在程序中你需一個無限循環.(例如一個監聽套接字的實例) 儘管 "while true" 能完成同樣的事, 但 "while 1" 是單步運算. 這招能提高你的Python性能.
>>> while 1:
>>> #do stuff, faster with while 1
>>> while True:
# 經本人實測 會快1毫秒
8. 使用list comprehension
從Python 2.0 開始,你可以使用 list comprehension 取代大量的 "for" 和 "while" 塊. 使用List comprehension通常更快,Python解析器能在循環中發現它是一個可預測的模式而被優化.額外好處是,list comprehension更具可讀性(函數式編程),並在大多數情況下,它可以節省一個額外的計數變量。例如,讓我們計算1到10之間的偶數個數:
>>> # the good way to iterate a range
>>> evens = [ i for i in range(10) if i%2 == 0]
>>> [0, 2, 4, 6, 8]
>>> # the following is not so Pythonic
>>> i = 0
>>> evens = []
>>> while i < 10:
>>> if i %2 == 0: evens.append(i)
>>> i += 1
>>> [0, 2, 4, 6, 8]
9. 使用xrange()處理長序列:
這樣可為你節省大量的系統內存,因為xrange()在序列中每次調用只產生一個整數元素。而相反 range(),它將直接給你一個完整的元素列表,用於循環時會有不必要的開銷。
10. 使用 Python generator:
這也可以節省內存和提高性能。例如一個視頻流,你可以一個一個字節塊的發送,而不是整個流。例如,
>>> chunk = ( 1000 * i for i in xrange(1000))
>>> chunk
<generator object <genexpr> at 0x7f65d90dcaa0>
>>> chunk.next()
0
>>> chunk.next()
1000
>>> chunk.next()
2000
11. 瞭解itertools模塊:
該模塊對迭代和組合是非常有效的。讓我們生成一個列表[1,2,3]的所有排列組合,僅需三行Python代碼:
>>> import itertools
>>> iter = itertools.permutations([1,2,3])
>>> list(iter)
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
12. 學習bisect模塊保持列表排序:
這是一個免費的二分查找實現和快速插入有序序列的工具。也就是說,你可以使用:
>>> import bisect
>>> bisect.insort(list, element)
你已將一個元素插入列表中, 而你不需要再次調用 sort() 來保持容器的排序, 因為這在長序列中這會非常昂貴.
13. 理解Python列表,實際上是一個數組:
Python中的列表實現並不是以人們通常談論的計算機科學中的普通單鏈表實現的。Python中的列表是一個數組。也就是說,你可以以常量時間O(1) 檢索列表的某個元素,而不需要從頭開始搜索。這有什麼意義呢? Python開發人員使用列表對象insert()時, 需三思. 例如:>>> list.insert(0,item)
在列表的前面插入一個元素效率不高, 因為列表中的所有後續下標不得不改變. 然而,您可以使用list.append()在列表的尾端有效添加元素. 挑先deque,如果你想快速的在兩插入或時。它是快速的,因為在Python中的deque用雙鏈表實現。不再多說。 :)
 檢查一個元素是在dicitonary或set是否存在 這在Python中非常快的。這是因為dict和set使用哈希表來實現。查找效率可以達到O(1)。因此,如果您需要經常檢查成員,使用 set 或 dict做為你的容器.
檢查一個元素是在dicitonary或set是否存在 這在Python中非常快的。這是因為dict和set使用哈希表來實現。查找效率可以達到O(1)。因此,如果您需要經常檢查成員,使用 set 或 dict做為你的容器.
>>> mylist = ['a', 'b', 'c'] #Slower, check membership with list:
>>> 『c' in mylist
>>> True
>>> myset = set(['a', 'b', 'c']) # Faster, check membership with set:
>>> 『c' in myset:
>>> True
 原生的list.sort()函數是非常快的。 Python會按自然順序排序列表。有時,你需要非自然順序的排序。例如,你要根據服務器位置排序的IP地址。 Python支持自定義的比較,你可以使用list.sort(CMP()),這會比list.sort()慢,因為增加了函數調用的開銷。如果性能有問 題,你可以申請Guttman-Rosler Transform,基於Schwartzian Transform. 它只對實際的要用的算法有興趣,它的簡要工作原理是,你可以變換列表,並調用Python內置list.sort() - > 更快,而無需使用list.sort(CMP() )->慢。
原生的list.sort()函數是非常快的。 Python會按自然順序排序列表。有時,你需要非自然順序的排序。例如,你要根據服務器位置排序的IP地址。 Python支持自定義的比較,你可以使用list.sort(CMP()),這會比list.sort()慢,因為增加了函數調用的開銷。如果性能有問 題,你可以申請Guttman-Rosler Transform,基於Schwartzian Transform. 它只對實際的要用的算法有興趣,它的簡要工作原理是,你可以變換列表,並調用Python內置list.sort() - > 更快,而無需使用list.sort(CMP() )->慢。
16. Python裝飾器緩存結果:
「@」符號是Python的裝飾語法。它不只用於追查,鎖或日誌。你可以裝飾一個Python函數,記住調用結果供後續使用。這種技術被稱為memoization的。下面是一個例子:
>>> from functools import wraps
>>> def memo(f):
>>> cache = { }
>>> @wraps(f)
>>> def wrap(*arg):
>>> if arg not in cache: cache['arg'] = f(*arg)
>>> return cache['arg']
>>> return wrap
我們也可以對 Fibonacci 函數使用裝飾器:
>>> @memo
>>> def fib(i):
>>> if i < 2: return 1
>>> return fib(i-1) + fib(i-2)
這裡的關鍵思想是:增強函數(裝飾)函數,記住每個已經計算的Fibonacci值;如果它們在緩存中,就不需要再計算了.
17. 理解Python的GIL(全局解釋器鎖):
GIL是必要的,因為CPython的內存管理是非線程安全的。你不能簡單地創建多個線程,並希望Python能在多核心的機器上運行得更快。這是因為 GIL將會防止多個原生線程同時執行Python字節碼。換句話說,GIL將序列化您的所有線程。然而,您可以使用線程管理多個派生進程加速程序,這些程 序獨立的運行於你的Python代碼外。
18. 像熟悉文檔一樣的熟悉Python源代碼:
Python有些模塊為了性能使用C實現。當性能至關重要而官方文檔不足時,可以自由探索源代碼。你可以找到底層的數據結構和算法。 Python的源碼庫就是一個很棒的地方:http://svn.python.org/view/python/trunk/Modules
結論:
這些不能替代大腦思考. 打開引擎蓋充分瞭解是開發者的職責,使得他們不會快速拼湊出一個垃圾設計. 本文的Python建議可以幫助你獲得好的性能. 如果速度還不夠快, Python將需要借助外力:分析和運行外部代碼.我們將在本文的第二部分中涉及.
第二部分
 調優給你的代碼增加複雜性. 集成其它語言之前, 請檢查下面的列表. 如果你的算法是"足夠好", 優化就沒那麼迫切了.
調優給你的代碼增加複雜性. 集成其它語言之前, 請檢查下面的列表. 如果你的算法是"足夠好", 優化就沒那麼迫切了.
1. 你做了性能測試報告嗎?
2. 你能減少硬盤的 I/O 訪問嗎?
3. 你能減少網絡 I/O 訪問嗎?
4. 你能升級硬件嗎?
5. 你是為其它開發者編譯庫嗎?
6.你的第三方庫軟件是最新版嗎?
2. 使用工具監控代碼, 而不是直覺
速度的問題可能很微妙, 所以不要依賴於直覺. 感謝 "cprofiles" 模塊, 通過簡單的運行你就可以監控Python代碼
「python -m cProfile myprogram.py」


3. 審查時間複雜度
控制以後, 提供一個基本的算法性能分析. 恆定時間是理想值. 對數時間復度是穩定的. 階乘複雜度很難擴展.
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
4. 使用第三方包
有很多為Python設計的高性能的第三方庫和工具. 下面是一些有用的加速包的簡短列表.
1. NumPy: 一個開源的相當於MatLab的包
2. SciPy: 另一個數值處理庫
3. GPULib: 使用GPUs加速代碼
4. PyPy: 使用 just-in-time 編譯器優化Python代碼
5. Cython: 將Python優碼轉成C

5. 使用multiprocessing模塊實現真正的並發
因為GIL會序列化線程, Python中的多線程不能在多核機器和集群中加速. 因此Python提供了multiprocessing模塊, 可以派生額外的進程代替線程, 跳出GIL的限制. 此外, 你也可以在外部C代碼中結合該建議, 使得程序更快.

6. 本地代碼
好了, 現在你決定為了性能使用本地代碼. 在標準的ctypes模塊中, 你可以直接加載已編程的二進制庫(.dll 或 .so文件)到Python中, 無需擔心編寫C/C++代碼或構建依賴. 例如, 我們可以寫個程序加載libc來生成隨機數.

總結:
閱讀 Zen of Python,在Python解析器中輸入 import this. 一個犀利的Python新手可能會注意到"解析"一詞, 認為Python不過是另一門腳本語言. "它肯定很慢!"
毫無疑問:Python程序沒有編譯型語言高效快速. 甚至Python擁護者們會告訴你Python不適合這些領域. 然而,YouTube已用Python服務於每小時4千萬視頻的請求. 你所要做的就是編寫高效的代碼和需要時使用外部實現(C/C++)代碼. 這裡有一些建議,可以幫助你成為一個更好的Python開發者:
1. 使用內建函數:
你可以用Python寫出高效的代碼,但很難擊敗內建函數. 經查證. 他們非常快速.

2.使用join()連接字符串.
你可以使用 "+" 來連接字符串. 但由於string在Python中是不可變的,每一個"+"操作都會創建一個新的字符串並複製舊內容. 常見用法是使用Python的數組模塊單個的修改字符;當完成的時候,使用 join() 函數創建最終字符串. >>> #This is good to glue a large number of strings
>>> for chunk in input():
>>> my_string.join(chunk)
3. 使用Python多重賦值,交換變量
這在Python中即優雅又快速:
>>> x, y = y, x
這樣很慢:
>>> temp = x
>>> x = y
>>> y = temp
4. 儘量使用局部變量
Python 檢索局部變量比檢索全局變量快. 這意味著,避免 "global" 關鍵字.
5. 儘量使用 "in"
使用 "in" 關鍵字. 簡潔而快速.
>>> for key in sequence:
>>> print 「found」
6. 使用延遲加載加速
將 "import" 聲明移入函數中,僅在需要的時候導入. 換句話說,如果某些模塊不需馬上使用,稍後導入他們. 例如,你不必在一開使就導入大量模塊而加速程序啟動. 該技術不能提高整體性能. 但它可以幫助你更均衡的分配模塊的加載時間.
7. 為無限循環使用 "while 1"
 有時候在程序中你需一個無限循環.(例如一個監聽套接字的實例) 儘管 "while true" 能完成同樣的事, 但 "while 1" 是單步運算. 這招能提高你的Python性能.
有時候在程序中你需一個無限循環.(例如一個監聽套接字的實例) 儘管 "while true" 能完成同樣的事, 但 "while 1" 是單步運算. 這招能提高你的Python性能. >>> while 1:
>>> #do stuff, faster with while 1
>>> while True:
>>> # do stuff, slower with wile True
# 經本人實測 會快1毫秒
8. 使用list comprehension
從Python 2.0 開始,你可以使用 list comprehension 取代大量的 "for" 和 "while" 塊. 使用List comprehension通常更快,Python解析器能在循環中發現它是一個可預測的模式而被優化.額外好處是,list comprehension更具可讀性(函數式編程),並在大多數情況下,它可以節省一個額外的計數變量。例如,讓我們計算1到10之間的偶數個數:
>>> # the good way to iterate a range
>>> evens = [ i for i in range(10) if i%2 == 0]
>>> [0, 2, 4, 6, 8]
>>> # the following is not so Pythonic
>>> i = 0
>>> evens = []
>>> while i < 10:
>>> if i %2 == 0: evens.append(i)
>>> i += 1
>>> [0, 2, 4, 6, 8]
9. 使用xrange()處理長序列:
這樣可為你節省大量的系統內存,因為xrange()在序列中每次調用只產生一個整數元素。而相反 range(),它將直接給你一個完整的元素列表,用於循環時會有不必要的開銷。
10. 使用 Python generator:
這也可以節省內存和提高性能。例如一個視頻流,你可以一個一個字節塊的發送,而不是整個流。例如,
>>> chunk = ( 1000 * i for i in xrange(1000))
>>> chunk
<generator object <genexpr> at 0x7f65d90dcaa0>
>>> chunk.next()
0
>>> chunk.next()
1000
>>> chunk.next()
2000
11. 瞭解itertools模塊:
該模塊對迭代和組合是非常有效的。讓我們生成一個列表[1,2,3]的所有排列組合,僅需三行Python代碼:
>>> import itertools
>>> iter = itertools.permutations([1,2,3])
>>> list(iter)
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
12. 學習bisect模塊保持列表排序:
這是一個免費的二分查找實現和快速插入有序序列的工具。也就是說,你可以使用:
>>> import bisect
>>> bisect.insort(list, element)
你已將一個元素插入列表中, 而你不需要再次調用 sort() 來保持容器的排序, 因為這在長序列中這會非常昂貴.
13. 理解Python列表,實際上是一個數組:
Python中的列表實現並不是以人們通常談論的計算機科學中的普通單鏈表實現的。Python中的列表是一個數組。也就是說,你可以以常量時間O(1) 檢索列表的某個元素,而不需要從頭開始搜索。這有什麼意義呢? Python開發人員使用列表對象insert()時, 需三思. 例如:>>> list.insert(0,item)
在列表的前面插入一個元素效率不高, 因為列表中的所有後續下標不得不改變. 然而,您可以使用list.append()在列表的尾端有效添加元素. 挑先deque,如果你想快速的在兩插入或時。它是快速的,因為在Python中的deque用雙鏈表實現。不再多說。 :)
14. 使用dict 和 set 測試成員:

>>> mylist = ['a', 'b', 'c'] #Slower, check membership with list:
>>> 『c' in mylist
>>> True
>>> myset = set(['a', 'b', 'c']) # Faster, check membership with set:
>>> 『c' in myset:
>>> True
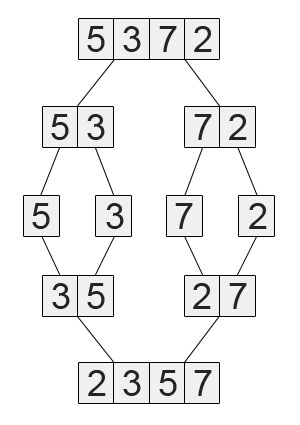
15. 使用Schwartzian Transform 的 sort():
16. Python裝飾器緩存結果:
「@」符號是Python的裝飾語法。它不只用於追查,鎖或日誌。你可以裝飾一個Python函數,記住調用結果供後續使用。這種技術被稱為memoization的。下面是一個例子:
>>> from functools import wraps
>>> def memo(f):
>>> cache = { }
>>> @wraps(f)
>>> def wrap(*arg):
>>> if arg not in cache: cache['arg'] = f(*arg)
>>> return cache['arg']
>>> return wrap
我們也可以對 Fibonacci 函數使用裝飾器:

>>> @memo
>>> def fib(i):
>>> if i < 2: return 1
>>> return fib(i-1) + fib(i-2)
這裡的關鍵思想是:增強函數(裝飾)函數,記住每個已經計算的Fibonacci值;如果它們在緩存中,就不需要再計算了.
17. 理解Python的GIL(全局解釋器鎖):
GIL是必要的,因為CPython的內存管理是非線程安全的。你不能簡單地創建多個線程,並希望Python能在多核心的機器上運行得更快。這是因為 GIL將會防止多個原生線程同時執行Python字節碼。換句話說,GIL將序列化您的所有線程。然而,您可以使用線程管理多個派生進程加速程序,這些程 序獨立的運行於你的Python代碼外。
18. 像熟悉文檔一樣的熟悉Python源代碼:
Python有些模塊為了性能使用C實現。當性能至關重要而官方文檔不足時,可以自由探索源代碼。你可以找到底層的數據結構和算法。 Python的源碼庫就是一個很棒的地方:http://svn.python.org/view/python/trunk/Modules
結論:
這些不能替代大腦思考. 打開引擎蓋充分瞭解是開發者的職責,使得他們不會快速拼湊出一個垃圾設計. 本文的Python建議可以幫助你獲得好的性能. 如果速度還不夠快, Python將需要借助外力:分析和運行外部代碼.我們將在本文的第二部分中涉及.
第二部分
有益的提醒,靜態編譯的代碼仍然重要. 僅例舉幾例, Chrome,Firefox,MySQL,MS Office 和 Photoshop都是高度優化的軟件,我們每天都在使用. Python作為解析語言,很明顯不適合. 不能單靠Python來滿足那些性能是首要指示的領域. 這就是為什麼Python支持讓你接觸底層裸機基礎設施的原因, 將更繁重的工作代理給更快的語言如C. 這高性能計算和嵌入式編程中是關鍵的功能. Python性能雞湯第一部分討論了怎樣高效的使用Python. 在第二部分, 我們將涉及監控和擴展Python.
1. 首先, 拒絕調優誘惑

1. 你做了性能測試報告嗎?
2. 你能減少硬盤的 I/O 訪問嗎?
3. 你能減少網絡 I/O 訪問嗎?
4. 你能升級硬件嗎?
5. 你是為其它開發者編譯庫嗎?
6.你的第三方庫軟件是最新版嗎?
2. 使用工具監控代碼, 而不是直覺
速度的問題可能很微妙, 所以不要依賴於直覺. 感謝 "cprofiles" 模塊, 通過簡單的運行你就可以監控Python代碼
「python -m cProfile myprogram.py」
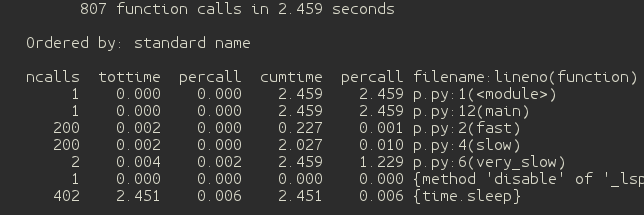
我們寫了個測試程序. 基於黑盒監控. 這裡的瓶頸是 "very_slow()" 函數調用. 我們還可以看到 "fast()" 和 "slow()"都被調用200次. 這意味著, 如果我們可以改善 "fast()" 和 "slow()" 函數, 我們可以獲得全面的性能提升. cprofiles 模塊也可以在運行時導入. 這對於檢查長時間運行的進程非常有用.

3. 審查時間複雜度
控制以後, 提供一個基本的算法性能分析. 恆定時間是理想值. 對數時間復度是穩定的. 階乘複雜度很難擴展.
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
4. 使用第三方包
有很多為Python設計的高性能的第三方庫和工具. 下面是一些有用的加速包的簡短列表.
1. NumPy: 一個開源的相當於MatLab的包
2. SciPy: 另一個數值處理庫
3. GPULib: 使用GPUs加速代碼
4. PyPy: 使用 just-in-time 編譯器優化Python代碼
5. Cython: 將Python優碼轉成C
6. ShedSkin: 將Python代碼轉成C++

5. 使用multiprocessing模塊實現真正的並發
因為GIL會序列化線程, Python中的多線程不能在多核機器和集群中加速. 因此Python提供了multiprocessing模塊, 可以派生額外的進程代替線程, 跳出GIL的限制. 此外, 你也可以在外部C代碼中結合該建議, 使得程序更快.
注意, 進程的開銷通常比線程昂貴, 因為線程自動共享內存地址空間和文件描述符. 意味著, 創建進程比創建線程會花費更多, 也可能花費更多內存. 這點在你計算使用多處理器時要牢記.
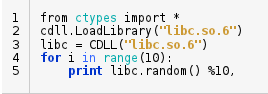
6. 本地代碼
好了, 現在你決定為了性能使用本地代碼. 在標準的ctypes模塊中, 你可以直接加載已編程的二進制庫(.dll 或 .so文件)到Python中, 無需擔心編寫C/C++代碼或構建依賴. 例如, 我們可以寫個程序加載libc來生成隨機數.
然而, 綁定ctypes的開銷是非輕量級的. 你可以認為ctypes是一個粘合操作系庫函數或者硬件設備驅動的膠水. 有幾個如 SWIG, Cython和Boost 此類Python直接植入的庫的調用比ctypes開銷要低. Python支持面向對象特性, 如類和繼承. 正如我們看到的例子, 我們可以保留常規的C++代碼, 稍後導入. 這裡的主要工作是編寫一個包裝器 (行 10~18).

總結:
我希望這些Python建議能讓你成為一個更好的開發者. 最後, 我需要指出, 追求性能極限是一個有趣的遊戲, 而過度優化就會變成嘲弄了. 雖然Python授予你與C接口無縫集成的能力, 你必須問自己你花數小時的艱辛優化工作用戶是否買帳. 另一方面, 犧牲代碼的可維護性換取幾毫秒的提升是否值得. 團隊中的成員常常會感謝你編寫了簡潔的代碼. 儘量貼近Python的方式, 因為人生苦短. :)
OSCHINA原創翻譯,轉載請註明出處:出處:OSCHINA
留言
張貼留言